- Published on
HTTP에 대해 정확히 알아보기 1편
- Authors

- Name
- 이주영
들어가기 앞서
HTTP는 웹 개발자로서 정확히 알아야 하는 개념이며 다른 개념들과 연관관계가 깊어 여러 개념들의 게이트웨이의 역할을 할 수 있다고 생각합니다. 그래서 이번 기회에 정복해보고자 합니다. 해당 블로그는 상당히 긴 내용을 다루고 있습니다. 그래서 모듈화 하여 총 3가지 포스트로 나누어 작성하려고 합니다.
1편 , 네트워크 기반 HTTP 사전 지식과 기본적인 HTTP 특징에 대해 알아보려고 합니다. 2편, HTTP의 메소드, 헤더, 상태코드에 대해 알아보려고 합니다. 3편, 실제 개발에서 HTTP에 대해 알아야 해결할 수 있는 문제들을 찾아보고 해결과정을 알아보려고 합니다.
HTTP 1편 시작해보겠습니다.
사전 지식
HTTP에 대해 보다 깊이 알기 위해선 HTTP를 통해 데이터를 보낼 때 거치는 TCP와 IP에 대해 이해하면 좋습니다.
기본적인 네트워크 지식 정리
OSI 7계층과 TCP/IP의 관계
OSI 7 계층과 TCP/IP의 관계는 한마디로 정의하면 개념과 구현의 관계입니다. 쉽게 생각해 보면 이론과 실제라고 생각할 수 있겠네요.
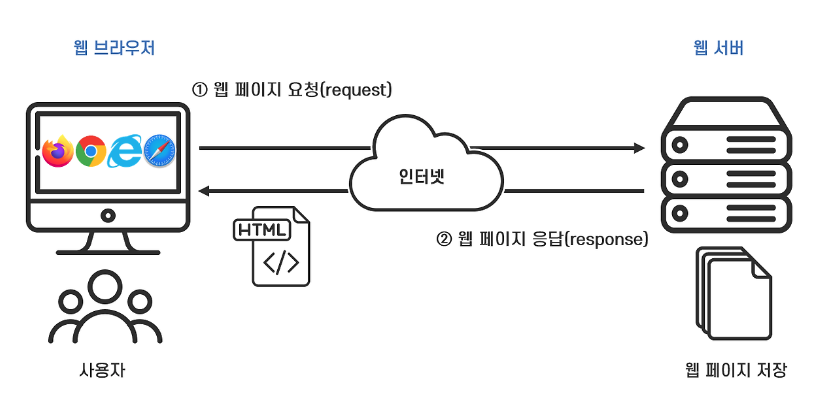
시작부터 이게 무슨 그림인가 싶지만 익숙해지는 게 네트워크 기본지식을 학습하는데 좋은 방법이라고 생각합니다. 아래의 이미지는 OSI 7 계층과 실제 구현된 TCP/IP 4 계층과 관련된 사진입니다.
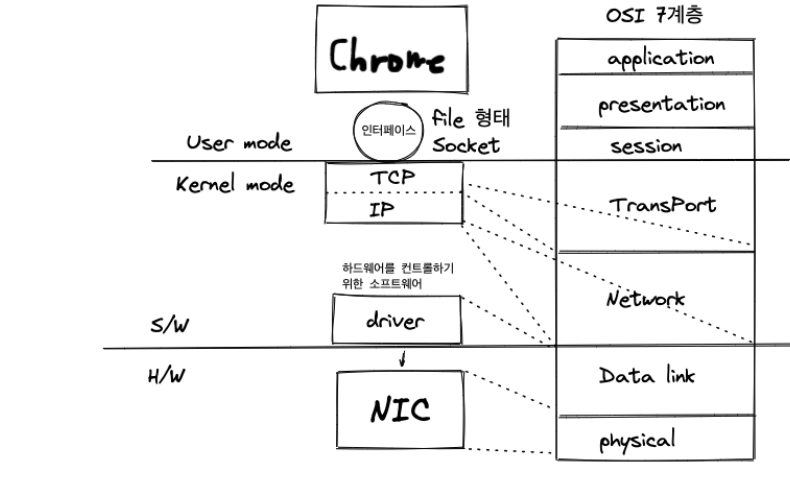
TCP/IP는 4 계층으로 구성되어 있으며 네트워크 액세스 계층, IP가 작동하는 인터넷 계층, TCP와 UDP가 있는 전송 계층, 마지막으로 응용 프로그램과 네트워크 간의 인터페이스를 제공하는 응용 계층이 있습니다. 오늘 알아볼 HTTP는 응용 계층에 존재하는 프로토콜입니다. TCP와 IP인 전송 계층과 인터넷 계층에 있군요. 살펴봅시다..
인터넷 프로토콜 (IP)란?
IP는 데이터 패킷이 네트워크를 통해 이동해서 올바른 곳에 도착할 수 있도록 데이터 패킷을 이동시키고 주소를 지정하기 위한 규칙의 집합입니다.
IP와 관련된 어휘 정리 패킷 : IP (인터넷) 계층의 데이터 단위입니다. ex) TCP (전송) 계층은 세그먼트입니다. 어느 정도의 암기가 필요합니다.
IP 주소란? 그리고 동작 방식
IP 주소는 인터넷에 연결하는 도메인의 할당된 고유 식별자입니다.
주로 일련의 숫자 형태이어서 사람들이 기억하기 어려움이 있죠. 그래서 DNS를 통해 숫자를 기억하지 않아도 되도록 변환하며 쉽게 접근할 수 있게 됩니다. 위에서 봤던 IP 패킷이란 게 있습니다.
IP 패킷에는 출발 주소와 도착 주소가 모두 포함되어 있습니다. 그로 인해서 라우터를 통해 도착 주소로 이동되는 것이죠.
IP 패킷이 뭘까요?
목적지 IP로 데이터를 보낼 땐, 그 데이터는 패킷이라고 불려지는 작은 단위로 쪼개져서 전달되게 됩니다. 패킷은 프로토콜에 따라 특정 구조를 띄는데 IP 패킷은 시작 주소와 목적지 주소 그리고 네트워크에 따라 전달할 패킷을 제어하는데 필요한 정보를 포함한 패킷이라고 할 수 있습니다.
IP 패킷의 구조 IP 패킷은 전송 데이터 패킷에 IP 헤더가 추가되어 생성됩니다. IP 헤더에는 위에서 말한 정보들이 포함되어있죠.
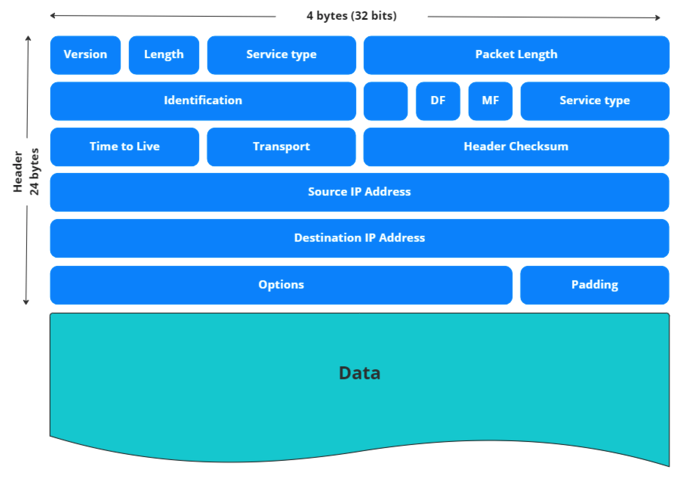
- 버전
- 총 길이
- 프로토콜
- Time to Live
- 소스 IP 주소
- 종결 IP 주소
- 전송 계층 프로토콜 종류 그외에도 여러가지가 존재합니다.
IP 패킷의 특징
- 패킷의 최대 크기는 MTU (1500 bytes) -> 1.4KB
TCP는 무엇인가요?
TCP(Transfer Control Protocol)은 단어가 시사하듯 전송을 제어하는 프로토콜입니다. 즉 데이터를 보내고 받는 '방법'을 지정합니다.
핵심
- 연결 개념이 존재합니다. (UDP는 존재하지 않음)
- 순서를 보장합니다. (UDP는 보장하지 않음)
**TCP와 관련된 어휘 정리 ** 세그먼트 : TCP (전송)계층의 단위는 세그먼트입니다. Port : IP안에서 특정 프로세스를 식별할 수 있게 해주는 번호입니다.
TCP도 IP와 같이 헤더를 통해 특정 정보를 포함해서 보냅니다. 여기서 눈여겨볼 것은 IP는 IP주소를 TCP는 Port 번호를 헤더에 추가한다는 것입니다. 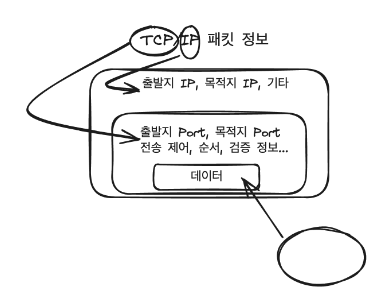
TCP는 데이터를 전송하기 전에 수신자와 연결을 설정하는 특징이 있습니다. 또한 TCP는 전송이 시작되면 모든 패킷이 순서대로 도착하도록 합니다. 수신이 확인되지 않은 경우는 누락된 패킷이 다시 전송되는 특징이 있습니다. TCP는 속도를 위해 설계된 것이 아닌 안정성을 위함입니다.
Port 번호란?!
포트 번호는 네트워크에서 프로세스 (실행 중인 프로그램)이나 서비스를 식별하는 데 사용되는 번호입니다. TCP 혹은 UDP를 통해 사용할 수 있고 데이터를 주고받는 프로세스가 TCP 헤더에 있는 포트 번호에 바인딩돼 해당 포트를 통해 통신하게 됩니다. 정리해 보면 여러 개의 서버와 통신할 수 있는 거죠!!
포트 종료에는 Well-known 포트(0~1023), Registered Ports (1024 ~ 49151) 그리고 동적 포트 번호 (49152 ~ 65535)를 가집니다.
TCP Header 형식
포트번호는 0부터 65535까지 사용할 수 있습니다. 정해진 port (well-known port) 중 HTTP와 HTTPS는 80번, 443번을 사용하고 있습니다.
TCP 헤더의 형식은 아래와 같습니다.
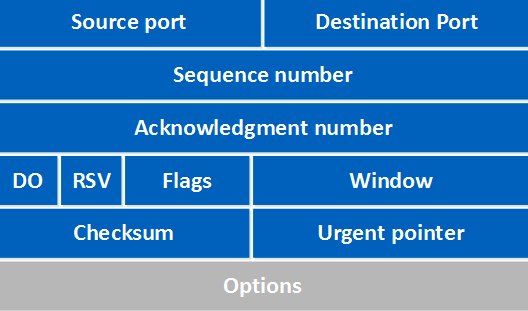
IP 헤더와 비슷한 형식이 보이네요! 하지만 IP와 다르게 Port 번호가 헤더에 존재하고 Sequence number와 Acknowledgement number가 보이네요!
Sequence number와 Acknowledgement number를 짚고 넘어가봅시다.
- Sequence number : TCP 세그먼트에 포함된 데이터의 순서를 나타냅니다. 즉 해당 일련 번호를 통해 도작 IP 주소에서 순서대로 재조립하는데 사용됩니다.
- Acknowledgement number : 수신자에서 송신자로 보내는 응답을 보낸 데이터의 마지막 바이트를 포함하고 있습니다. 이를 통해 도착 IP로 데이터 패킷이 올바르게 수신됐고 기대되는 데이터의 일련 숫자를 알고 있음을 출발 IP에게 알려줍니다.
IP의 한계였던 패킷의 도착 순서를 보장할 수 없었던 문제 (라우팅으로 인함)와 안정성을 해결해주는 헤더의 정보라고 할 수 있습니다.
TCP, 어떻게 동작하는거지?
1. 연결 설정 (3-way handshake)
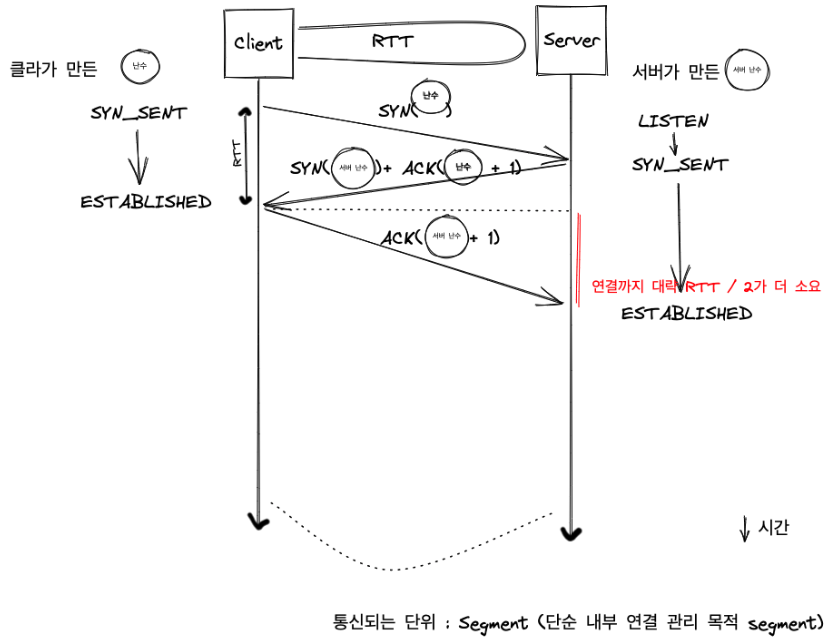
2. 데이터 전송 소켓을 통해 들어온 데이터는 TCP 세그 먼트로 분할되어 전송됩니다. 데이터는 위에서 살펴본 Sequence number를 가지고 있어야 하고 목적지 호스트에서는 해당 값을 활용하여 새그먼트의 순서를 추적합니다.
3. 흐름 제어 TCP는 흐름 제어 메커니즘을 사용해서 목적지 호스트에서 처리할 수 있느 속도로 데이터를 전송합니다. (와... 어떻게 이게 가능한거지? )
목적지 호스트가 쪼개진 패킷을 받고 응답으로 자신의 윈도우 크기를 ACK 패킷에 포함해서 보냅니다. 그걸 통해 출발지 호스트는 목적지 호스트의 버퍼의 여유공간을 알 수 있습니다.
4. 혼잡 제어 TCP는 네트워크 혼잡을 감지합니다. 혼잡이 발생하면 전송 속도를 줄이는 메커니즘을 제공합니다.
5. 연결 해제 ( 4-way handshaking )
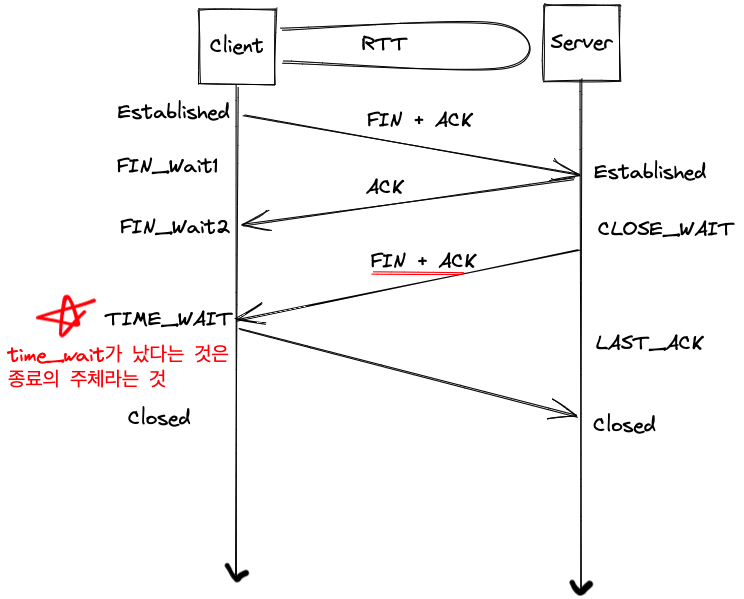
- 클라이언트는 서버에게 FIN(Finish)을 보냅니다.
- 서버는 FIN에 대한 ACK를 보냅니다.
- 서버가 데이터 전송을 마치면 클라이언트에게 FIN을 보냅니다.
- 클라이언트는 FIN에 대한 ACK를 보내고 연결을 종료합니다.
UDP/IP는 무엇인가!
User Datagram Protocol은 단어를 통해 알 수 있는 것은 User(사용자 혹은 응용 프로그램) 수준의 네트워크가 가능하다는 것입니다. 즉, Usermode에 있는 응용 프로그에서 주로 사용할 수 습니다. 왜냐하면 TCP보다 안정적이진 않으나, 빠르게 데이터를 송수신할 수 있기 때문입니다.
UDP 헤더 형식
TCP보다 단순한 UDP 헤드 형식 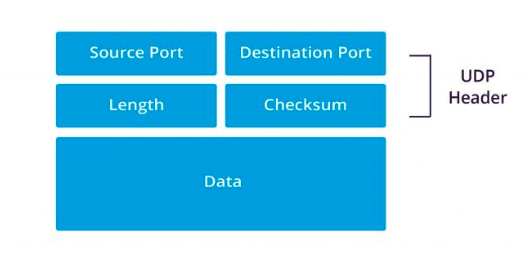
정리
위의 개념을 정리해 보면 복잡한 인터넷 망에서 메시지를 보내기 위해선 IP가 있어야 합니다. 하지만 IP 만으로는 신뢰성, 안정성 그리고 프로세스 식별들에 한계가 존재했습니다. 이런 한계를 극복하기 위해 TCP, 전송 계층을 통해 해결했습니다.
UDP는 IP와 비슷한, IP와 거의 흡사한 프로토콜입니다. 그리고 Port는 같은 IP 안에서 동작하는 애플리케이션 구분을 위해 사용합니다.
데이터 전송시 큰 개요 정리
https://www.google.com:443/search?q=hello&hl=ko을 브라우저에서 검색할 경우
- DNS 조회 -> IP와 Port 취득 (복잡한 과정 생략)
- 웹 브라우저가 HTTP 요청 메세지 생성
- 스켓 라이브러리를 통해 TCP/IP 계층으로 데이터 전달
- TCP/IP 계층에서 패킷을 생성하고 HTTP 메세지를 포함한다.
- 네트워크 인터페이스에서 서버로 전달
- 패킷 껍데기 버리고 HTTP 메시지를 구글 서버에서 분석
- 구글 서버에서 HTTP 응답 메시지 생성
- 패킷 동일하게 만들고 브라우저로 응답
이제 HTTP의 기본적인 특징과 메소드를 알아봅시다.
본론
HTTP란?!
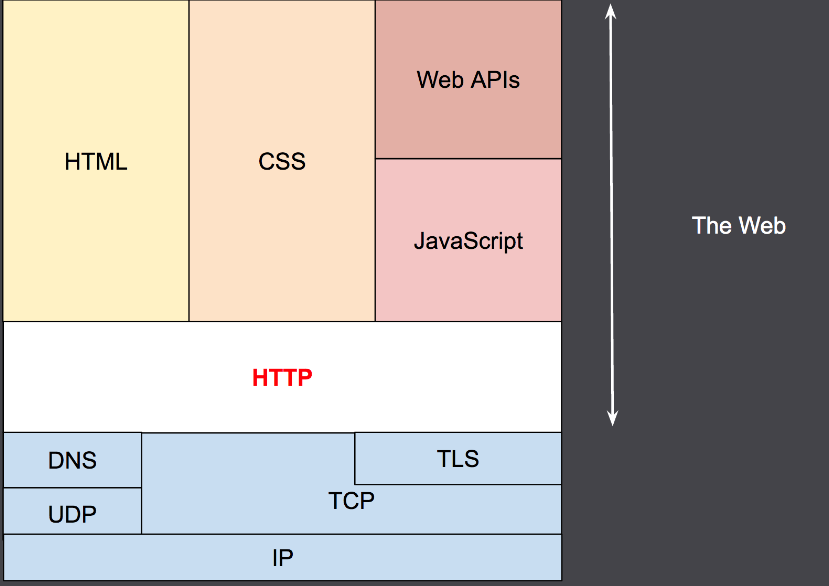
위의 이미지를 통해 무엇을 알 수 있을까요?! 지금까지 HTTP 위에서 HTML과 CSS 그리고 JS를 활용해서 상호작용이 가능한 웹 사이트를 만드는데 집중했습니다. 더군다나 여러 라이브러리와 프레임워크를 통해서 보다 쉽게 만들 수 있었죠. 이전 블로그에서 브라우저 렌더링을 정리하며 HTML, CSS, JS가 브라우저 화면에 픽셀단위로 그려지는 과정을 정리해 보았습니다. [궁금하신 분은 여기로 ]
HTTP는 TCP/IP 4계층의 응용 계층에 존재하며 브라우저가 우리 몰래 해주는 일련의 과정들을 이해하는데 도움이 될 뿐만 아니라 실제 개발에서도 유용합니다.
HTTP 정의
Hypertext Transfer protocol의 준말로 웹에서 데이터를 주고 받는 서버-클라이언트 모델의 프로토콜입니다. 즉 웹 브라우저가 서버와 통신하는 규칙이라고 생각할 수 있습니다
HTTP에 대한 기본적인 지식 정리
1. 클라이언트 서버 구조
클라이언트 서버 구조는 일종의 웹 아키텍처로 자리 잡았다고 생각합니다. 프론트엔드는 사용자와의 상호작용을 통해 데이터를 조회하고 변경하고 삭제하는 기능을 사용자가 사용할 수 있도록 창구를 만들어주는 역할이라고 한다면 서버는 창구를 통해 들어온 요청에 대한 일련의 작업을 진행하고 응답값을 클라이언트로 전달해 주며 진행되는 방식이죠. 클라이언트와 서버를 나눈 구조로 관심사 분리가 이루어져 클라이언트에서는 UI에 집중하면 되고 서버에서는 복잡한 비즈니스 로직을 처리하는데만 집중할 수 있게 됩니다.
2. 무상태라는 것의 의미
"상태가 없다?!"는 의미는 서버가 클라이언트 상태를 가지고 있지 않는다는 것. 즉 이전 상태를 유지하지 않는 것을 의미합니다. 이전 상태를 가지고 있지 않는 것이 무엇인지 이해하기 위해 예제를 살펴봅시다.
로그인을 통해 장바구니에 담는 과정을 살펴봅시다.
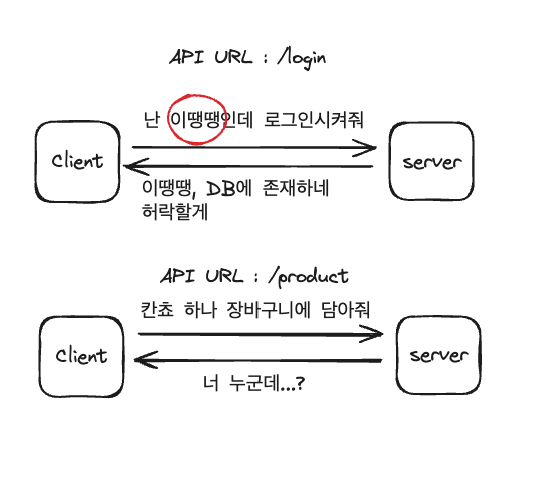
우선 클라이언트가 지정한 주소로 로그인 데이터와 함께 로그인 요청을 보냅니다. 그러면 서버에서 일련의 과정을 통해 검증 이후 응답을 주겠죠. 그렇게 메인 페이지로 들어오게 됐고 상품들을 살펴본 후 특정 상품을 장바구니에 담으려고 합니다. 그런데 서버는 이전 단계에서 이미 로그인을 했음에도 불구하고 다시 물어보는 겁니다. 그리고 데이터가 없으면 서버는 401 상태 코드를 통해 클라이언트에게 미인가 처리가 되었다고 알려주죠
그럼 어떻게 해야할까요? 아래와 같이 인증 데이터를 또 보내주면 됩니다.
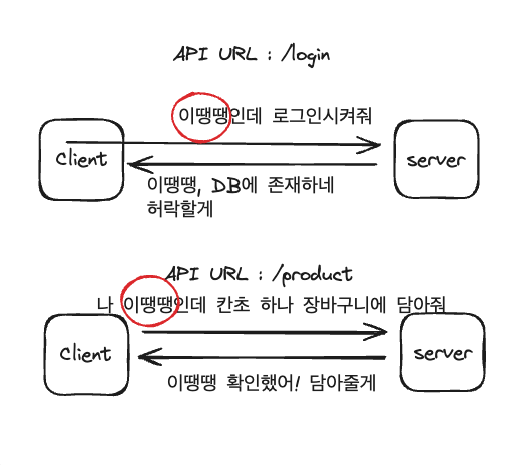
Stateless 하다는 것은 이전 상태를 유지하지 않는다는 것을 의미한다고 했습니다. 그렇다면 위의 예시에서 이전 상태는 로그인 상태를 말하는 것이겠죠. 서버에게 인증 상태를 포함해서 요청하면 서버는 로직을 통해 확인 후 응답을 줍니다.
서버 요청시 불필요하게 중복된 데이터를 포함해서 보내는 것 같지 않나요?! 하지만 중요한 장점이 있습니다.
상태가 클라이언트에 있으니 서버는 클라이언트의 상태에 의존하게 됩니다. 그러니 서버 확장에 용이하겠죠. 예를 들어 서버에서 상태를 유지한다고 가정했을 때 장바구니의 요청하는 과정에서 서버가 죽게 돼, 다른 서버로 대체할 경우 죽은 서버의 상태는 사라졌기에 복원할 수 없어 에러가 발생하게 됩니다. 즉 서버가 상태를 유지하지 않도록 설계를 하면 서버가 바뀌어도 장애가 나지 않기 때문에 서버의 확장성이 기하급수적으로 증가할 수 있던 것이었습니다.
하지만 이 또한 보완해야 할 점이 있겠죠. 클라이언트가 데이터를 추가적으로 서버로 보내는 과정에서 서버 요청을 최소화와 보안을 모두 얻기 위해 브라우저 쿠키와 서버 세션 방식, 웹 브라우저 저장소를 사용해서 구현할 수 있겠습니다.
3. HTTP 메세지
 HTTP 메시지 구조를 살펴봅시다.
HTTP 메시지 구조를 살펴봅시다.
참고 : https://tools.ietf.org/html/rfc7230#section-3
HTTP 요청 메시지 이거 문서 보고 정리해보자 (5월 17일 추가) HTTP 응답 메시지 이거 문서 보고 정리해보자 (5월 17일 추가) **HTTP 헤더 ** HTTP 전송에 필요한 모든 부가 정보
HTTP 바디
- 실제 전송할 데이터
- HTML 문서, 이미지, 영상 등 byte로 표현할 수 있는 모든 데이터 전송 가능
HTTP 메소드
URI는 리소스만 식별하는 데 사용해야 하고 해당 행위는 분리해야 합니다. 그렇기에 행위는 HTTP 메소드를 통해 분리할 수 있는 거죠!! 리팩터링 (알리고 올리고) 예제로 살펴보자!!
메소드 종류
- GET : 리소스 조회
- POST : 요청 데이터 처리, 등록에 사용
- PUT : 리소스를 대체, 해당 리소소가 없으면 생성 (폴더에 파일 추가할때 덮어쓰기를 생각하면 됩니다.)
- PATCH : 리소소 부분 변경
- DELETE
1. GET
- 데이터는 쿼리를 통해 전달
- 메시지 바디를 사용해서 전달할 수 있다!!?? 최근 스팩에서는 막지 않지만 실무에서는 바디를 사용하지 말자!! 참고 : https://datatracker.ietf.org/doc/html/rfc7231#section-4.3.1
식별자는 구현에 해당하며 각 구현은 GET에 대한 응답으로 대상 리소스의 현재 표현을 선택하고 전송하는 방법을 관리합니다. 클라이언트는 요청에서 Range 헤더 필드를 전송하여 GET의 의미를 "범위 요청"으로 변경할 수 있습니다. 이는 선택된 표현의 일부만을 전송하도록 요청합니다([RFC7233]). GET 요청 메시지 내의 페이로드는 정의된 의미가 없습니다. GET 요청에 페이로드 본문을 전송하면 일부 기존 구현에서 요청을 거부할 수 있습니다. GET 요청에 대한 응답은 캐시 가능합니다. Cache-Control 헤더 필드([RFC7234]의 5.2절)에 의해 다르게 명시되지 않는 한, 캐시는 이를 사용하여 후속 GET 및 HEAD 요청을 충족시킬 수 있습니다.
2. POST
- 요청 데이터 처리
- 메시지 바디를 통해 서버로 요청 데이터 전달
- 서버는 요청 데이터를 처리
- 메시지 바디를 통해 들어온 데이터를 처리하는 모든 기능을 수행합니다.
- 주로 전달된 데이터로 신규 리소스 등록, 프로세스 처리에 사용.
조금 더 깊이 들어가보시죠.
The POST method requests that the target resource process the representation enclosed in the request according to the resource's own specific semantics. For example, POST is used for the following functions (among others): (https://datatracker.ietf.org/doc/html/rfc7231#section-4.3.3)
POST 메서드는 대상 리소스가 요청에 포함된 표현을 리소스의 특정 의미에 따라 처리하도록 요청합니다.
예를 들어
- HTML Form
- 게시판, 뉴스 그룹, 댓글
- 새로운 리소스 생성 시
- 기존 자원에 데이터 추가
핵심은 리소스 URI에 POST 요청이 오면 요청 데이터를 어떻게 처리할 지 리소스마다 따로 정해야한다는 것입니다.
포스트는 3가지 경우에 사용합니다.
- 새 리소스 생성 (등록)
- 요청 데이터 처리
- 단순 데이터를 생성 및 변경하는 것을 넘어서 프로세스를 처리해야하는 경우, 즉 상태가 변경되는 것을 말한다.
- 다른 메서드로 처리하기 애매한 경우
- JSON으로 조회 데이터를 넘결때 GET 사용하지 못할 때 POST를 사용
3. Put
- 리소스를 대체
- 리소스가 있으면 완전히 대체 -> 즉 덮어쓰기 개념
- 리소스가 없으면 생성
- 중요한 것은 클라이언트가 리소스를 식별하는 것
4. Patch
- PUT 매소드의 데이터 덮어쓰기에 관한 문제를 해결하기 위해 중간에 등장
- 부분 수정이 가능해진다.
- 중요한 것은 클라이언트가 리소스를 식별하는 것
5. DELETE
메소드 속성
1. Safe 호출했을때 리소스!가 변경되지 않는 것을 안전하다고 한다. (자원에 관해서만 고려하면 된다.)
2. Idempotent 멱등 한 번 호출하든 두 번 호출하든 100번 호출하든 결과가 똑같아야합니다. 순수 함수의 개념과 유사합니다.
멱등한 메소드
- GET: O
- PUT: O
- DELETE : O
- POST : X 예를 들면 결제를 생각해볼 수 있습니다.
그래서 멱등은 언제 쓰나요?
- 자동 복구 메커니즘
- 서버가 TIMEOUT 등으로 정상 응답을 못줄때 클라에서 같은 요청을 다시 해도되는가의 판단 근거로 멱등으로 답할 수 있다. GET,PUT,DELETE는 멱등하기에 여러번 호출할 수 있다는 것.
멱등은 외부 요인으로 중간에 리소스가 변경되는 것은 고려하지 않습니다. 동일한 요청에 한해서 고려한다고 생각하면 됩니다.
3.캐시 가능
- GET, HEAD, POST, PATCH 캐시 가능
- 실제로는 GET과 HEAD는 캐시 가능 -> POST, PATCH는 본문 내용까지 캐시 키로 고려해야하는데 구현이 쉽지 않다고 한다.